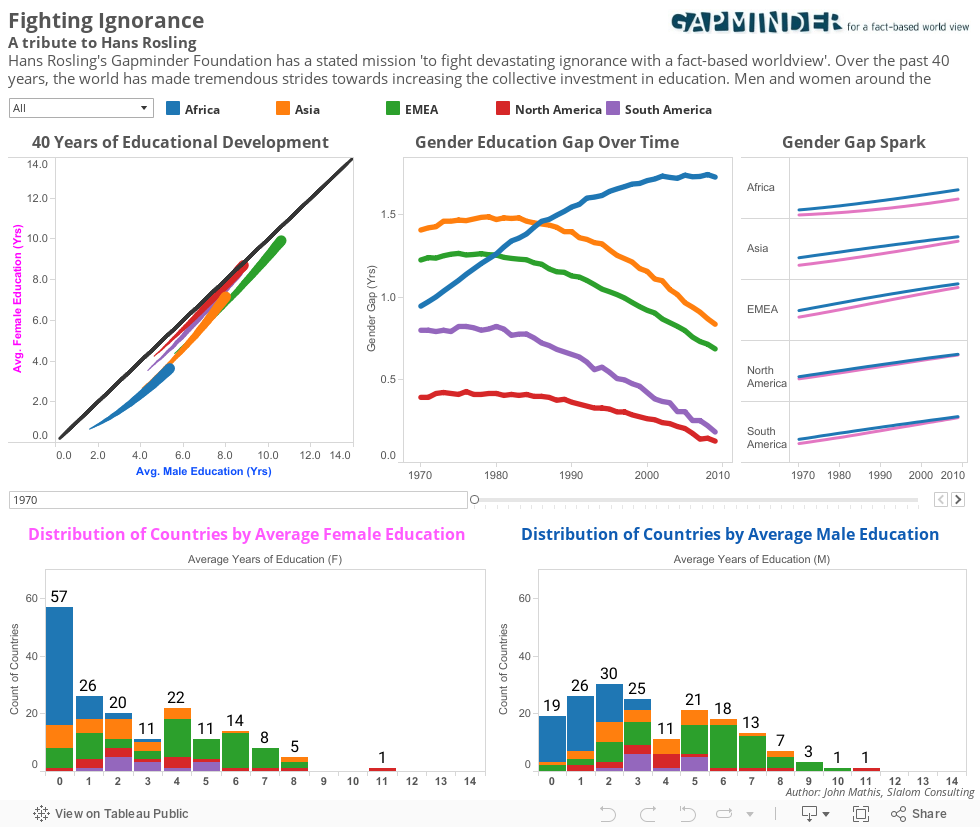
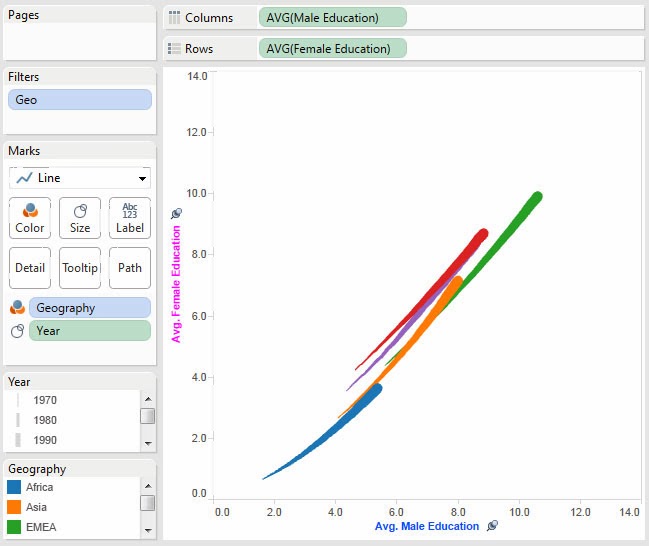
I recently had the opportunity to compete in the 2014
Tableau Conference Iron Viz. For those who are unfamiliar, the Iron Viz is a
competition which pits three data visualization enthusiasts against each other
to create the best possible visualization in 20 minutes - live onstage in front of over a
thousand people. It was the fastest 20 minutes of my
life. After the dust had settled, my dashboard, which analyzed the Yelp
reviewers (as opposed to businesses), won the championship! Without further ado, here was my final product:

Below is the story of my road to the Iron Viz championship…
I earned my spot in the finals by winning the feeder competition
Elite
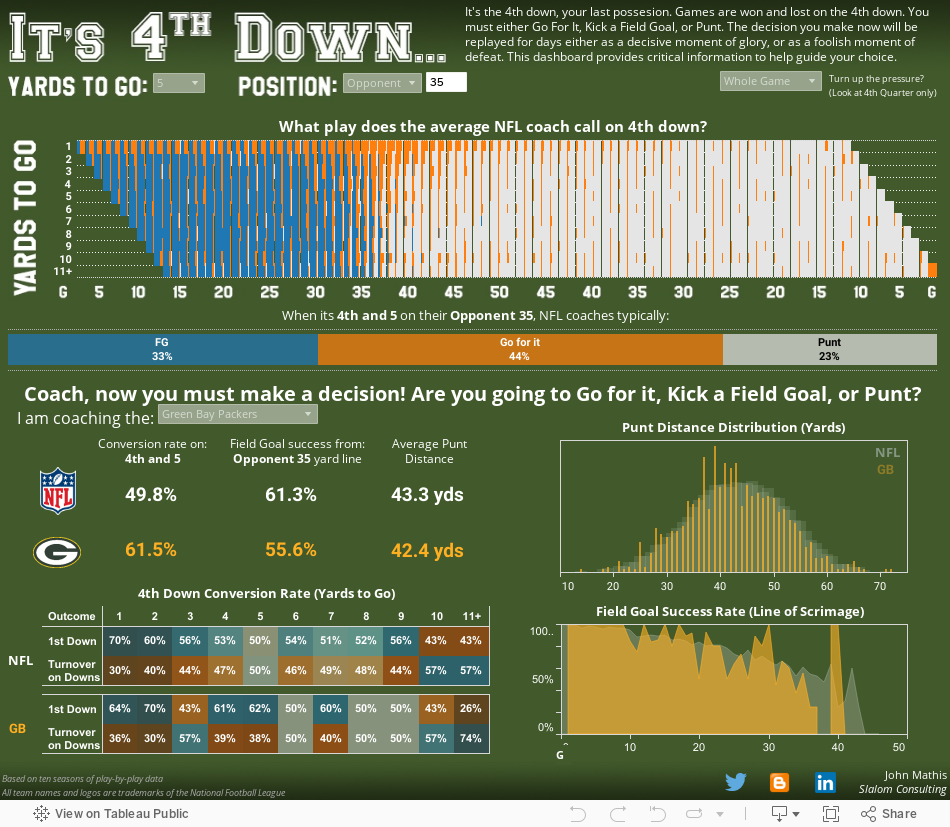
8 Sports Viz Contest with my dashboard It’s 4th
Down. My two other competitors, Jeffrey
Shaffer and Jonathan
Trajkovic, earned their spots by winning the quantified self and
storytelling competitions respectively. I got to know them over the course of
the week in Seattle and they are both really great guys that create fantastic
content for the Tableau community.
The inspiration for my viz was a seafood restaurant I found
on Yelp years ago when we were vacationing in a new city and looking for
dinner. I remember it only had a few reviews and at 3 overall stars wasn’t looking
that promising, but I clicked it anyways. There were two 4 stars reviews and a
single 1 star review. I don’t remember the exactly wording, but the 1 star
review basically said 'I hate seafood and I hate this restaurant'. I remember
thinking ‘Why should I trust someone’s review of a seafood restaurant when they
don’t like seafood?’ When I was looking at the Yelp data for Iron Viz, this all
came back to me and my idea was born: 'Who should you trust on Yelp?'
Tactically my Iron Viz strategy basically involved taking advantage of the strengths of Tableau:
- Easy exploration to see what data was available and how it was structured
- ‘Speed-of-thought’ analysis to see what insights I could pull out of the data.
- Rapid creation and iteration to arrive at a final design
- Rapid creation and iteration to start from scratch after I decided I didn’t like my ‘final’ design at the last minute
Ease of Exploration
Although we knew we were going to be competing months in
advance, to make it more challenging, we were only given the data several days ahead of time - which left only a few days to explore and practice. Pulling the data apart quickly revealed it was just over
1 million Yelp reviews going back to 2004 for three cities (Las Vegas, Phoenix
and Edinburgh, UK). The structure of the data had some implications given that the
data is a large denormalized table. For example, because businesses are repeated
for each review, the SUM of the businesses’ review are meaningless. Understanding
the data structure was critical to using the right aggregations for our
metrics.
Speed of Thought
I knew I wanted to evaluate the reviewers themselves, but
how best to do that? I quickly created a few different calculated fields before
settling on my key metric, Reviewer Error. Reviewer Error measures how far that
particular reviewer’s rating varied from the overall Yelp consensus. For individual reviews this isn’t meaningful (people can have a bad
experience at a good business) but when looking in aggregate you can get an
idea how close or far someone is from the overall consensus. This is
technically the Root Mean Square Deviation. It was easy to create this
metric in Tableau:
Reviewer Error = SQRT(SUM(([Review
Score]-[Business Score])^2)/SUM([Number of Records]))
My first exploration was segmenting reviewers by a few key
dimensions including that user’s overall review average, how many votes that
user had accrued, how many fans they had, and how many years they were Yelp
elite. There were some very clear trends in the data:

Key Takeaways:
- Reviewers whose average rating was less than 3, or worse, less than 2 had a very large error. This is likely because some people likely go on Yelp, write a bad review, and never write any other reviews.
- Both the number of votes a person had received and the number of fans they had were correlated to a reduction in error.
- Reviewers with at least one year Yelp elite had a lower error, but additional years of Yelp elite didn’t lead to any significant further reduction of error.
In layman’s terms, a trusted reviewer typically has an
average review greater than three stars, has many votes and fans, and has at
least one year as Yelp elite. I practiced building these charts and a couple of
detail charts in the two days leading up to the competition. After multiple rounds of practice I got it down to
under 20 minutes. Of course, as you can see in my final dashboard, I did not include these charts.
Rapid Design and Iteration
About 18 hours before the competition, after looking at my
dashboard for the 100th time, I decided the analysis was too static
and didn’t tell the story of any individual reviewers. I decided to go back
to the drawing board. I ended up rebuilding almost the entire dashboard the night before.
I kept my Reviewer Error metric and just started poking
around and slicing different ways until I settled on looking at individual
reviewers in a scatterplot. The Reviewer Error / Number of Reviews is a great
scatterplot chart that shows a regression to
the mean as would be expected, but also has a skew to it that indicates the
frequent reviewers on Yelp really are more accurate than the overall average.
More interesting, the scatterplot quickly illuminates the outliers, or
reviewers who are either very good or very bad at reviewing. I’ll start with
the good: Norm.
Norm has over 1,000 reviews, an error of .72 stars, and
minimal bias in either direction. We can see he has been very consistent over
time both in how many reviews he has left and what his average review is. I
feel that Norm has a good sense of what to expect from a business. If I pick one
of his recent reviews (link from the tool tip in bottom right chart), a 4 star
review of ‘Delhi Indian Cuisine’, I can see he wrote a detailed review with
pictures. Clicking
on his profile reveals he has thousands of votes and many years at Yelp
elite. Given my prior segmentation, this was not a surprise.


Now let's go to the other extreme, Diana. At nearly three times Norm's error, her error is 2.01 stars with negative .76 star
bias over 120 reviews. When we select her, we can she is an 'all or nothing' type woman. All of her
reviews are either 5 stars or 1 star. From her average rating and bias we can tell she
is, on aggregate, a harsh critic and really hands out the 1 star reviews like it is going out of style.
Selecting her recent review of Zoyo
Neighborhood Yogurt we can see she gives it a 1 because of ‘flies and bugs’.
Clicking
her profile we can see her four most recent reviews are all 1 star reviews
and every single one of them complains about the flies or insects. It makes you
wonder if you can really trust her reviews at all.
Closing Thoughts
In closing, I wanted to discuss a couple of comments I received from the judges:
- I used Red/Blue gradient instead of an Amber/Blue gradient
- I did not include a color legend
Although we were hurried for time, I did consciously think
about both of these aspects prior to creating the viz and wanted to share my
thoughts here. Please disagree with me in the comments!
- As for the red/blue gradient, I wanted my dashboard to have a ‘Yelp feel’ and they prominently use red throughout their site. I used red for this reason. I used blue so there was clear contrast against high and low reviews even though on the low end yelp uses grey/yellow hues.
- I didn’t use a legend and instead opted for semantically resonant colors. High/low reviews are red/blue respectively where red is 1) hot (popular) 2) aligned to Yelp and 3) reinforced subtlety through all three charts on the right of the dashboard. There could be some argument that red is ‘bad’ such as in a status report, but when it comes to reviews and stars specifically, I've often found them red.
I have a list of about a dozen more things I would do to improve this dashboard, but let me tell you, 20 minutes goes by fast! In the spirit of the Iron Viz, I made no further updates to this workbook since I put the mouse down in the competition. The 20 minutes onstage belies the
effort all three of us put in preparing for the showdown. My competitors put together great vizes and I thought Jeffrey's roulette wheel was a creative way to blend the data with story of Vegas (though losing to a pie chart would have been rough).
John
John